Maelstrom: mitigating datacenter-level disasters by draining interdependent traffic safely and efficiently
https://blog.acolyer.org/2018/10/24/maelstrom-mitigating-datacenter-level-disasters-by-draining-interdependent-traffic-safely-and-efficiently/amp/
- 4+ year of experience dealing with datacenter outages at Facebook
- Maelstrom = system FB use in prod to mitigate and recover from DC-level disasters
- Idea: drain traffic away from the failed DC, move it to another DC
- 4+ years, 100+ disasters => 1 disaster per 2 weeks!! (DC-wide incident)
- 3 valuable contributions:
- The description of the Maelstrom
- An explanation of drain tests as they are practiced at FB
- Hard-won wisdom and expectation settings for rolling out similar capabilities in your own organization
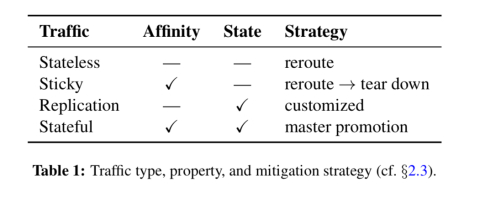
- Traffic types:
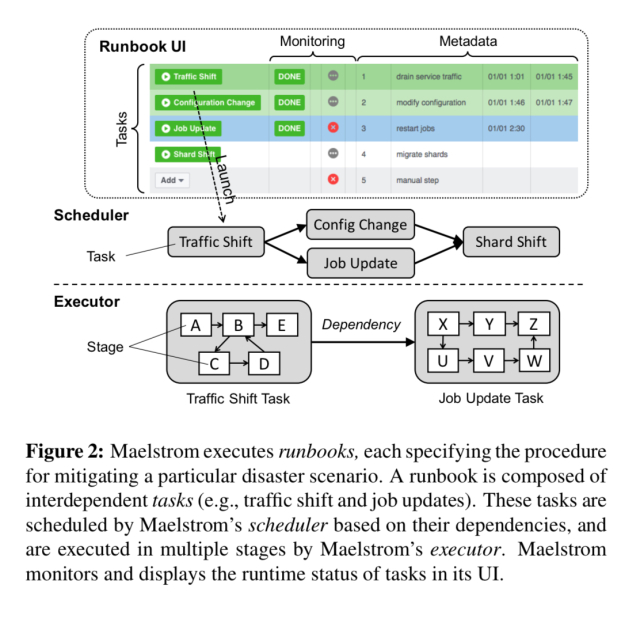
- Maelstrom is used to execute recovery runbooks:
- to drain traffic out of the datacenter
- to restore traffic back
- Runbooks are made of tasks. Dependencies between tasks.
- Every service maintains its own service-specific runbook
- If an entire datacenter is down - datacenter evacuation runbook is used. Such a runbook aggregates a collection of service-specific runbooks.
- Collection of task templates
- Task has health metrics, pre-conditions, post-conditions and dependencies
- Library for common operations (LB to alter traffic, migrate shards, etc)
- Maelstrom Runtime: Scheduler (correct order of tasks) + Executor (execute tasks + validate results)
- Maelstrom compares the duration of each task to 75th percentile (stuck? -> alert)
- Feedback loop to pace the speed of traffic drains based on monitoring
- Drain Testing
- Runbook should be changed if the system is changed -> stale
- Drain test - is to verify and build trust in the runbook