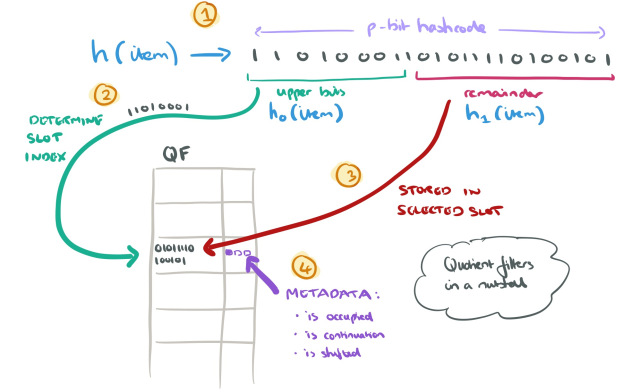
дополнительный runends бит-вектор, хранящий 1 если слот содержит последний remainder в ряду.


RANK(B,i) - возвращает кол-во 1-чек в B до позиции i
SELECT(B,i) - возвращает индекс первой 1-цы в B
обе функции будут бегать по occupieds, runends, remainders - плохо с кэшом, поэтому
добавлен offsets массив, который хранит дистанцию от слота i до runend, который соответствует этому слоту i. Для оптимизации, сохраняют только для каждого 64-го слота (uint8) -> 2.125 бита на слот
Т.е. делят на блоки по 64 записи, которые хранятся вместе -> все операции хорошо оптимизируются на machine-word операции PDEP, TZCNT
Counting Quotient Filters
добавляют подсчет количества к RSQF
variable-size counters (счётчики переменного размера) -> эффективно по размеру для любых распределений (разряженно-плотных)
если элемент присутствует более, чем однажды - тогда следующий за remainder слот хранит количество раз этот элемент присутствует.
CQF разделяет remainder или счетчик т.к. счетчик увеличивается, и любые изменения -> число.
Есть трюки
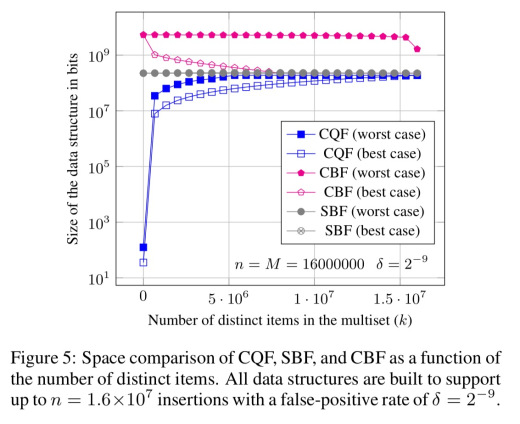
Сравнение использование места


CQF лучше почти всегда.
CQF может быть сделан мультитредовым (шарды, лочатся всегда по два)
Сравнение по производительности:
CQF в несколько раз лучше Bloom FIlter, хотя тот не поддерживает счетчик. И на порядок-два лучше Counting Bloom Filter(CBF)