Gliush Notebook
Notes about IT, work, and life
Notes for episode-0160
Hijacking Bitcoin: Routing Attacks on Cryptocurrencies
http://hackingdistributed.com/2017/05/01/bgp-attacks-on-btc/
- биткоин кажется защищенным.
- атака направленная на “распространение данных”, использующая “Internet routing infra”
- Большие Internet service providers (ISPs) уже сидят в центре передачи, через них идет большой поток траффика. Он plaintext, им очень просто ее подменять, блокировать, или генерировать свой
- Вопрос - насколько bitcoin подвержен?
- Выпускаем paper https://btc-hijack.ethz.ch/files/btc_hijack.pdf
- Биткоин очень централизован. 20% биткоин нод расположены на 100 IP prefixes. (сейчас всего около 600K IP prefixes). Некоторые ISP видят большую часть трафика. Поэтому атака может получиться
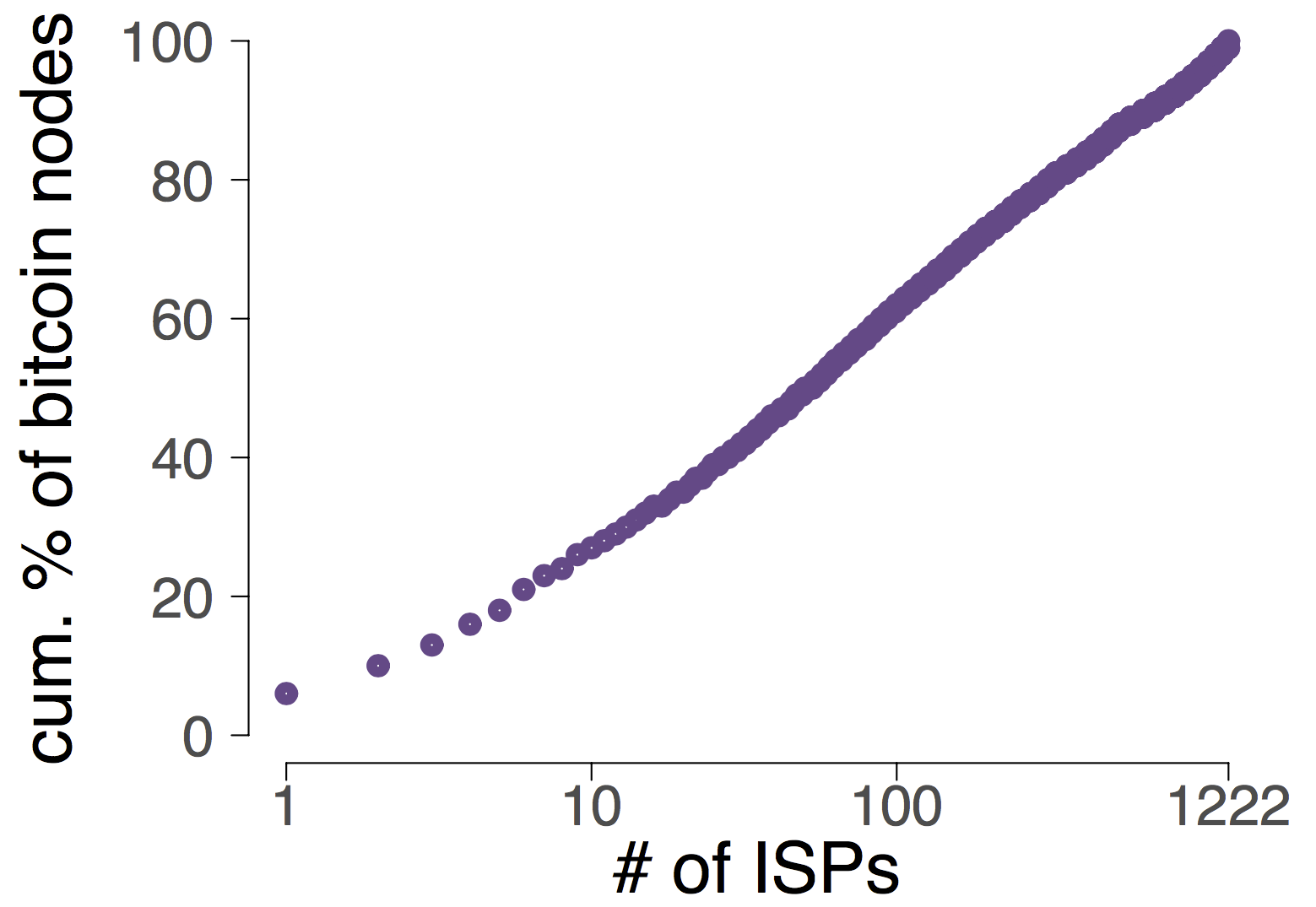
- Изоляция 50% узлов требует небольших усилий, на порядки меньше текущих атак. Любой зловредный ISP с доступом к routing infra может проводить атаку которая станет эффективной уже спустя минуты после начала
- ISP должен задерживать пропагацию блоков (до 20мин)
- Они утверждают, что уже сейчас наблюдают подобные атаки
- Partitioning attacks: разделить Bitcoin сеть на 2+ несвязные части. Уязвимости в Border Gateway Protocol (BGP), который не проверяет источник объявления маршрута (BGP Hijacks). Это очень эффективно, поскольку небольшое кол-во IP префиксов нужно “исправлять”. 50% сети - с помощью изменений в маршрутах для 39 префиксов.
- В некоторых случаях могут образоваться связи (в тех участках сети, которые не разделялись) между “разорванными” сетями, но как в бумаге показывается, атакующие могут уменьшать размер “оторванной части”. Т.е. это сложнее, но выполнимо.
- Цель разделения - чтобы транзакции в мЕньшей половине отверглись сетью. Особенно полезно, если есть есть конфликтующие записи (в одни и те же биткоины)
- Delay attacks: задерживать трафик до 20 мин (потом его источник будет перепосылать другим маршрутом)
- Как избежать?
- Максимизация разных соединений
- Ноды должны мониторить поведение коннектов
- e2e encryption, хотя это не поможет для partition attack
- Цель исследования - поднять интерес сообщества к необходимости защищаться от атак.
S3 on Digital Ocean
https://blog.digitalocean.com/introducing-spaces-object-storage/
- $5 per month: 250GB of storage + 1TB outbound bandwidth
- additional storage: $0.01 per GB transferred and $0.02 per GB stored
- Spaces - scales automatically, NYC3 today, AMS3 before EOY, all others - in 2018
- Files stored in Spaces: encrypted with 256-bit AES-XTS full disk enc
End-To-End Arguments in System Design
- Статья рассказывает про принципы дизайна, которые помогают в правильном месте расположить определённую функциональность в распределенной системе.
- Основная деятельность дизайнера - правильно продумать систему
- Нет ничего нового, просто многие используют эти правила без осознания, и данная статья просто артикулирует эти правила.
- Многие функции могут быть реализованы на разных уровнях: коммуникационная подсистема, клиентом, или везде.
- Полностью написать функциональность можно только если она будет работать при поддержке приложения (знания + абстракции), поэтому невозможно это сделать на уровне коммуникационной подсистемы
- Этот аргумент они называют “end-to-end argument”, и в дальнейшем используют по всей статье.
- Пример “передача файла”
- Разбили на стадии, показали список проблем (hardware, ошибка при чтении, при передаче, …)
- 1 подход - каждую стадию сделать полностью “правильной” (уменьшая вероятность ошибки на каждом шагу). Проблема - стадии не полностью изолированные, ошибки при копировании, космические лучи и т.д., поэтому на уровне выше все равно надо делать проверку. Проверки при чтении файлов (+checksum), проверка при пересылке на каждом пакете и т.д.
- 2 подход - end-to-end проверка и повтор. Если проблемы редки - ок. При этом дополнительные проверки на каждой стадии - лишь лишняя трата ресурсов.
- Пример из MIT: Была сеть с хорошей проверкой каждой пересылки между hop-ами, программисты понадеялись на нее, не делали доп проверок. Однако в железе были проблемы, которые проявлялись один раз из 1M пересылок. ПРишлось исправлять.
- Проверка на коммуникационном уровне улучшает производительность. Вероятность ошибки - экспоненциально увеличивается с размером файла, время пересылки файла экспоненциально уменьшается. Поэтому проверка каждого пакета нужна.
- Поэтому баланс (tradeoff) - на производительности, но нет проблем с корректностью. Если ненадежная пересылка - будет много проблем и часты пересылки. Если слишком много проверок на низком уровне - будет уменьшение производительности потока. И иметь ввиду, что у нас все равно будут проверки на уровне приложения (пример про передачу голоса, когда небольшие ошибки лучше, чем небольшая задержка)
- Иногда лучшая производительность может быть достигнута если проверки на верхнем уровне: нижний уровень шарится между несколькими приложениями (а не всем нужен полный набор проверок), нижняя система может не иметь некоторой информации, которая необходима для оптимизации
- Проверку можно сделать и на верхнем уровне: систематически делать чексумму переданного, и сверятся на источнике.
- Аналогичные примеры:
- Delivery Guarantees (важно сообщать доставлено или нет. Иногда нужно сообщать “обработано или нет”, иногда надо сообщать результат обработки)
- Secure transmission of data (управление ключами, доставление до криптования и после разкприптования,
- Duplicate message suppression
- Гарантия FIFO message delivery
- Transaction management
- Все примеры из реальной жизни, суммирования опыта из разных статей.
- Многие проблемы, обсуждаемые о распределенных системах - это end-to-end argument
IMHO: База, которую нужно знать про распределенные системы, и многообразие trade-off, которые могут встречаться. Не самый легкий язык, длинные предложения, сложные примеры. Но когда втянешься - ок.